01 介绍
近日,清华大学自动化系成像与智能技术实验室和电子工程系智能感知集成电路与系统实验室联合提出一款全模拟光电集成计算芯片,该芯片在国际上首次实现了光电计算在系统级性能上超越高性能GPU,计算速度超过三千倍,能效超过四百万倍,这一突破证明了光子计算在各类AI任务中的优越性。相关成果以“面向高速视觉任务的全模拟光电芯片”为题发表在《自然》杂志上。
02 研究背景
目前提升计算性能的主流准则摩尔定律在过去十余年中已经放缓并接近过时,电子晶体管的尺寸正在逼近物理极限,提升计算速度和能效刻不容缓,而新的计算架构是突破的关键。光电计算以其极高的并行性和速度被认为是未来颠覆性计算架构的有力竞争者。多年来,全球知名研究团队提出了各种光电计算架构。但将光电计算芯片直接替换现有电子设备并应用于系统级应用,还存在几个关键瓶颈:
1. 在单芯片上集成大规模光计算单元(可控神经元),同时控制误差累积程度。
2. 实现高速、高效的片上非线性。
3. 提供光计算与电子信号计算之间的高效接口,以适应当前电子驱动的信息社会。目前,单次模数转换所需的能量比光计算中每一步乘法和加法的功耗高出几个数量级,掩盖了光计算的性能优势,使光计算芯片难以在实际应用中真正竞争。
03 研究创新点
针对这些国际难题,团队创造性地提出了模拟电子与模拟光学相结合的计算框架,将用于视觉特征提取的大规模衍射神经网络与基于基尔霍夫定律的纯模拟电子计算集成在单芯片上,绕过了ADC速度、精度、功耗的物理瓶颈,突破了单芯片大规模集成计算单元、高效非线性、高速光电接口三大关键瓶颈。在三分类ImageNet等任务中,ACCEL芯片系统实现了4.6 Peta-OPS的系统级计算速度,是现有高性能光学计算芯片的400多倍,同时也是模拟电子计算芯片的4000多倍。ACCEL的系统级能效达到74.8 Peta-OPS/W,比现有的高性能光学计算、模拟电子计算、GPU、TPU等架构提升两千到数百万倍的效率。
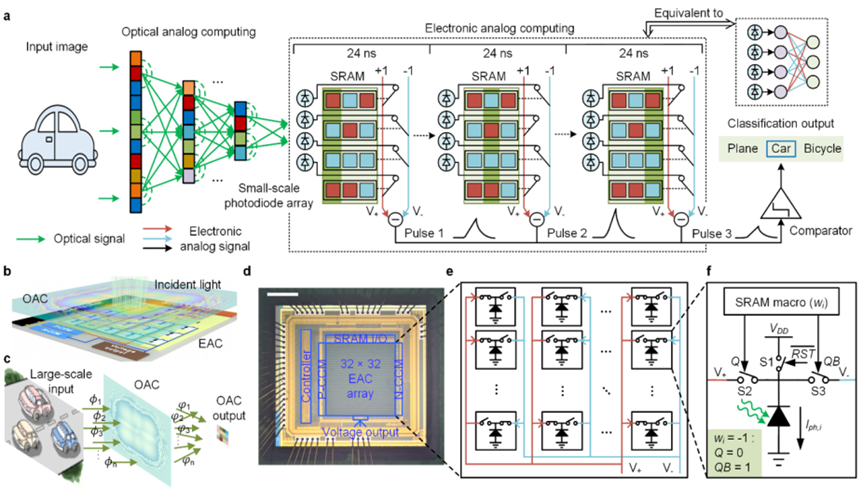
图1.ACCEL的架构和工作原理
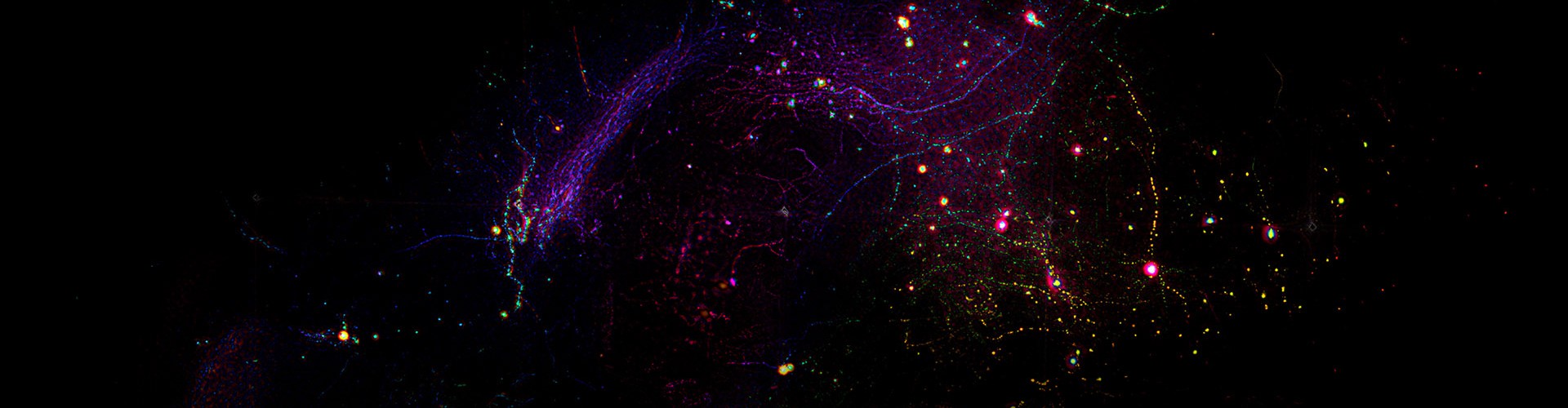
此外,在现实自动驾驶等超高速视觉计算任务中,超高的计算速度必然伴随着极短的每帧曝光时间,从而导致极低的曝光能量。研究团队提出了另一种系统级解决方案:基于光学和电子模块互补物理优势的联合设计。光学模块在并行提取特征的同时,以无监督的方式学习编码光强收敛到某些特征点的方式,在极低的总光强下增强局部光强,从而提高相应光电二极管的信噪比。同时,利用电子模块的可重构性,团队开发了自适应训练算法,有效纠正了前面多层光学模块的处理和对准误差。在训练过程中,他们还引入了对低光噪声环境的建模。论文结果表明,与单一光学计算或模拟电子计算模块相比,ACCEL芯片在各种光强,尤其是低光下的精度显著提高。此外,论文还展示了使用非相干光直接计算交通场景,确定车辆运动方向的实验。非相干光计算由于缺乏相位关系,容易受噪声影响,使得高性能光计算无法直接应用于自动驾驶、自然场景感知等实际场景。ACCEL芯片创新性地提出利用噪声鲁棒性实现非相干光计算,实现了在手机手电筒等非相干光照明下进行计算,并提供了视频演示。
04 总结和展望
该项工作不仅提出了一种具有卓越性能的颠覆性芯片架构,还为一系列阻碍光学计算实现的瓶颈问题提供了工程解决方案。它独特地表明,光学计算的未来发展可能并非仅仅追求“全光”架构,而是实现光学计算与数字社会的深度融合,相得益彰。这一思路使得光学计算芯片从理论上的高计算速度和能效到复杂视觉场景下的实际系统级应用成为可能。清华大学戴琼海院士、方璐副教授、乔飞副研究员、吴嘉敏助理教授为本文通讯作者;博士生陈一彤、麦麦提·那扎买提、许晗博士为共同第一作者;孟瑶博士、周天贶助理研究员、博士生李广普、范静涛研究员、魏琦副研究员也参与了这项研究。该项目得到科技部2030“新一代人工智能”重大专项、国家自然科学基金杰出青年科学基金、基础科学中心项目等资助。
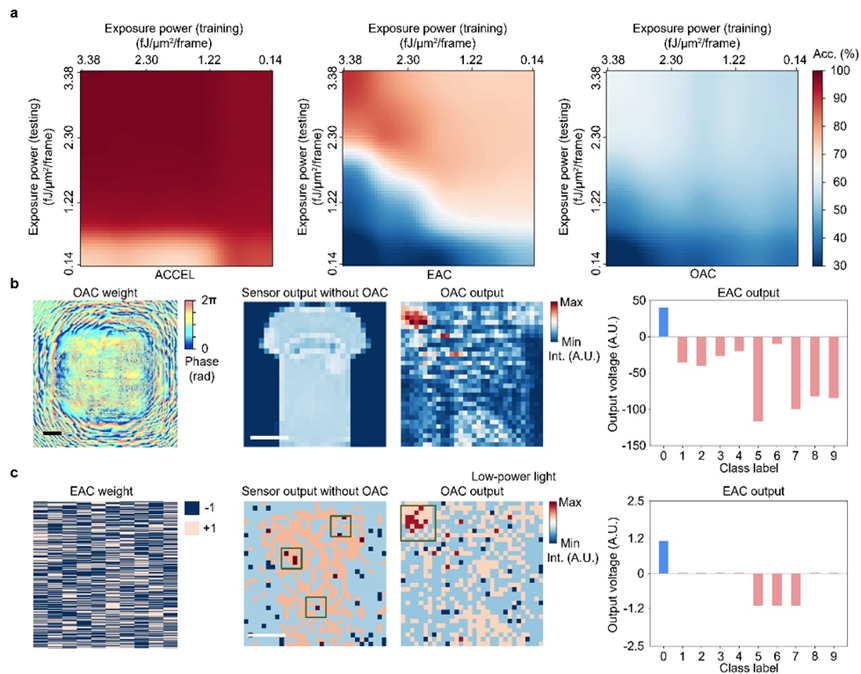
图2.在不同曝光强度和任务下的ACCEL性能
 邮箱:qhdai@tsinghua.edu.cn
邮箱:qhdai@tsinghua.edu.cn 地址:清华大学中央主楼三楼
地址:清华大学中央主楼三楼 传真:+86 10 62773433
传真:+86 10 62773433