智能光芯片“太极”赋能160 TOPS/W大规模通用计算
光电智能计算作为近年来新兴的计算模态,在后摩尔时代展现出远超传统硅基电学计算的通量与能效,有望解决人工智能领域的算力与功耗难题。然而,现有智能光计算面临通用传播模型不明、计算架构缺失、计算规模受限等桎梏,其计算任务往往局限于简单的字符分类、基本的图像处理等。对于亟需高算力与高能效的复杂大模型智能计算,光的高性能潜力难以施展。其痛点是光的计算优势被困在了不适合的电架构中,计算规模难以扩展,通用智能计算难以实现。
针对大规模光电智能计算难题,清华大学电子工程系方璐副教授课题组、自动化系戴琼海院士课题组,构建了智能光计算的通用传播模型,摒弃了传统电学深度计算范式,另辟蹊径,首创了分布式广度光计算架构Taichi,研制了大规模干涉-衍射异构集成芯片,实现了160 TOPS/W(每焦耳160万亿次运算)的通用智能计算,相关工作近期发表于国际顶级期刊Science。
化深为广,分布式广度光计算架构。课题组建立自顶向下的编码拆分-解码重构机制,将复杂智能任务化繁为简,拆分为多通道高并行的子任务,构建分布式‘大感受野’浅层光网络对子任务分而治之,突破物理模拟器件多层深度级联的固有计算误差。相异于电学神经网络普遍依赖网络深度以实现复杂的计算与功能,Taichi架构源自光计算独特的 ‘全连接’与‘高并行’属性,化深度计算为广度计算,为实现规模易扩展、计算高并行、系统强鲁棒的通用智能光计算探索了新路径。
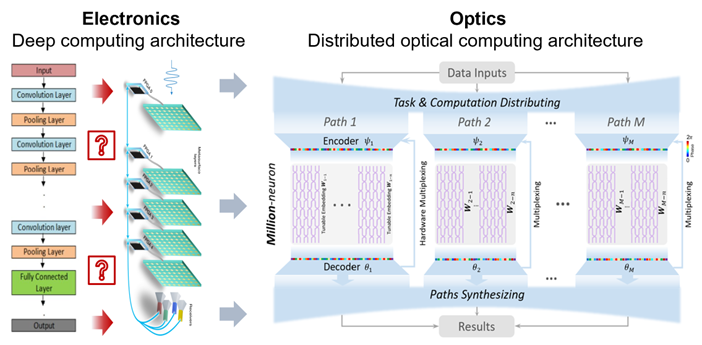
图1.化“深”为“广”:Taichi分布式广度光计算架构
两仪一元,干涉-衍射融合计算芯片。以周易典籍‘易有太极,是生两仪’为启发,建立衍射-干涉传播模型,刻画衍射光计算大规模并行优势与干涉光计算灵活重构特性,提出衍射编码-干涉特征计算-衍射解码的融合计算方法,研制了干涉-衍射异构集成智能光芯片,实现片上大规模通用光计算。更进一步,受益于光的高速传播特性,将衍射编解码与干涉特征计算进行部分/整体重构复用,以时序复用突破通量瓶颈,自底向上支撑分布式广度光计算架构Taichi。
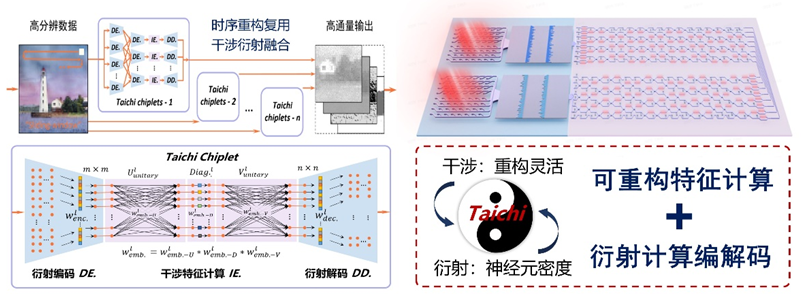 图2.两仪一元:干涉-衍射融合计算芯片
图2.两仪一元:干涉-衍射融合计算芯片
系统实测结果表明,Taichi具备879 T MACS/mm^2的面积效率与160 TOPS/W的能量效率(超现有主流商用智能AI芯片(NVIDIA A100)约2个数量级),首次赋能光计算实现自然场景千类对象识别、跨模态内容创作生成等人工智能复杂任务。Taichi在ImageNet数据集得到87.34%的百分类准确度,在Omniglot数据集得到91.89%的千分类准确度,实现了不同艺术家风格的音乐创作与纹理图像生成。Taichi将为百亿像素大场景光速智能分析、百亿参数大模型训练推理、毫瓦级低功耗自主智能无人系统提供算力支撑。通用大规模光计算从无极而至太极,以致万物化生。课题组希望Taichi可以在如今大模型通用人工智能蓬勃发展的时代,以光子之道,为高性能计算探索新灵感、新架构、新路径。
该研究工作以“大规模光芯片太极赋能160-TOPS/W通用人工智能”(Large-scale photonic chiplets Taichi empowers 160 TOPS/W artificial general intelligence)为题,发表在《科学》(Science)上。清华大学电子工程系为论文的第一单位,方璐副教授、戴琼海教授为论文的通讯作者,电子系博士生徐智昊、博士后周天贶(清华大学水木学者)为论文第一作者。
该课题受到科技部2030“新一代人工智能”重大项目、国家自然科学基金委杰青项目、基础科学中心项目,清华大学-之江实验室联合研究中心支持。
 邮箱:qhdai@tsinghua.edu.cn
邮箱:qhdai@tsinghua.edu.cn 地址:清华大学中央主楼三楼
地址:清华大学中央主楼三楼 传真:+86 10 62773433
传真:+86 10 62773433